Let's Code It: Static Site Generator with Rx.js
Originally published at StrongBlogLast post, we went over building a Static Site Generator (SSG) in Node.js. We used Promises for flow control, and that worked for reading each Markdown input file, transforming it into HTML, and writing that to disk, once per file. What if we instead of running this build process once per input file, we want it to run once per input file every time that input file is created or changed?
If our goal is to map a sequence of events over time (file creation or modification) to one or more operations (building Markdown to HTML and writing to disk), it's very likely Observables are a good fit! In this blog post, we'll look at how to use Observables and RX.js to create a SSG with built-in, incremental watch rebuilds, and with with multiple output streams (individual posts and blog index page).
This post loosely follows the demo project here, so if you prefer to look at all the code at once (or run it) you can do so.
What is RX.js
Observables can be confusing so reading a more detailed intro is advisable. Here I'll give a simplified explanation of Observables that is inadequate to understand them fully, but will hopefully be enough for this blog post!
As alluded to, Observables are a tool for modeling and working with events over time. One way to conceptualize Observables if you are familiar with Promises is to think of an Observable as a Promise that can emit multiple values. A Promise has the following "things it can do:"
- Emit an error (and settle the Promise)
- Emit a value (and settle the Promise)
The things an Observable can do are:
- Emit an error (like
reject) - Emit a value
- Emit a "complete" notification
The key difference is that that emitting a value and "settling" (called "completing" in RX.js Observables) are split into separate actions in Observables, and because emitting a value does not "complete" an Observable, it can be done over and over.
To illustrate this comparison further, with code, let us imagine a new utility method for constructing Promises called Promise.create. It behaves the same as the Promise constructor, but the signature of its function argument is slightly different.
// Promise constructor
const p1 = new Promise(function settle(resolve, reject){
if(foo){ resolve(value); }
else{ reject('Error!'); }
});
p1.then(console.log);
// Promise.create (imaginary API)
const p2 = Promise.create(function settle(settler){
if(foo){ settler.resolve(value); }
else{ settler.reject('Error!'); }
});
p2.then(console.log);
As you can see, Promise.create takes a settle function which receives an object with resolve and reject methods, rather than separate resolve and reject functions. From here it is a short step to Rx.Observable.create:
const o = Rx.Observable.create(function subscribe(subscriber) {
try{
while(let foo = getNextFoo()){
subscriber.next(foo); // emit next value
}
subscriber.complete(); // emit "complete"
}
catch(e){
subscriber.error(e); // emit "error"
}
});
When you want to use the results of a Promise, you attach a function via .then. With an Observable, when you wish to use the results to produce side effects, you attach an "Observer" via .subscribe:
myPromise.then(foo => console.log('foo is %s', foo))
.catch(e => console.error(e));
myObservable.subscribe({
next: foo => console.log('next foo is %s', foo),
error: e => console.error(e),
complete: () => console.log('All done! No more foo.')
})
Observers and Subscribers
In the style of programming with Observables that RX.js allows, tasks are often conceptualized as being composed of two parts: Observables (inputs), and Subscriptions or side effects (outputs). Side effects describe what you want to ultimately do with the values from an observable.
If you describe your goals as side effects, you can work backward to figure out what sort of Observables you need to create to provide the values those side effects need. For example, if you wish a counter to be incremented each time a button is clicked, "increment the counter" is the side effect, and you need an Observable of button clicks for that increment function to "subscribe" to.
For our static site generator, we have the following high-level goals:
- Write to disk an updated HTML version of each post:
- When the post input file is created
- When the post input file is changed and it results in different output
- Write to disk an updated blog index page:
- When we start our script
- Each time a post's metadata (title, description, etc.) is changed
The Observables we can map to each of these goals are:
parsedAndRenderedPosts$: emits post output each time a post is created or changed. Subscribe to this and write the new post contents to disk on each emit.latestPostMetadata$: emits a collection of the latest metadata when the script starts or the metadata for a post changes. Subscribe to this and write the rendered index page to disk on each emit.
Each of these two Observables will be composed of or created as a result of other Observables. As we build these up, we'll learn about different methods Rx.js has for creating and transforming Observables. Let's begin!
Goal 1: Write Posts
We know each of our Observables should emit based on file changes and additions, so we'll start by creating an Observable of file changes and additions called changesAndAdditions$. The chokidar module can be used to create an event emitter that emits change and add events on filesystem changes, so let's start there:
const chokidar = require('chokidar');
const dirWatcher = chokidar.watch('./_posts/*.md');
We want to create Observables of file changes & additions so we can manipulate & combine them with Rx.js. Rx.js provides a utility method to create an Observable from EventEmitter by event name. We are interested in the add event and the change events, so let's use fromEvent to create Observables of them:
const Rx = require('rxjs');
// note: `add` is emitted for each file on startup, when chokidar first scans the directory
const newFiles$ = Rx.Observable.fromEvent(dirWatcher, 'add');
const changedFiles$ = Rx.Observable.fromEvent(dirWatcher, 'change');
Now newFiles$ will emit a new value (a filename) when dirWatcher emits an add event, and changedFiles$ behaves similarly with change events. We can create an observable of both of these events by using .merge.
const changesAndAdditions$ = newFiles$.merge(changedFiles$);
Mapping Filename to File Contents
To get the file contents, we can .map the name of the file to the contents of that file by using a function that reads files. Reading a file is (typically) an asynchronous operation. If we were using Promises, we might write a function that takes a filename and returns a Promise that will emit the file contents. Similarly, using Observables, we use a function that takes a filename and returns an Observable that will emit the file's contents.
Just as Promise.promisify will convert a callback based function to one that returns a Promise, Rx.Observable.bindNodeCallback converts a callback based function to one that returns an Observable:
const fs = require('fs');
const readFileAsObservable = Rx.Observable.bindNodeCallback(fs.readFile);
const fileContents$ = changesAndAdditions$
.map(readFileAsObservable) // map filename observable of file contents
.mergeAll(); // Unwrap Observable<"file contents"> to get "file contents"
fileContents$
.subscribe(content => console.log(content)); // log contents of each file
Now we'll log the contents of each file as it is created or changed. Let's take a closer look at our use of .mergeAll: readFileAsObservable is a function that takes a String (filename) as input and returns an Observable<String> (an observable of the "file contents" string).
This means that by mapping changesAndAdditions$ over readFileAsObservable, we took an Observable<String> (an observable of strings, namely, file names) and converted each String value to a new Observable<String>. This means we have Observable<Observable<String>>: an Observable of Observables of Strings.
We don't actually want an Observable of file contents, we want filename in, file contents out. For this reason we use .mergeAll to "unwrap" the file contents strings from the inner Observables as they are emitted. If you are confused by this, don't worry: it is in fact confusing! For now it's only important to understand that .mergeAll converts Observable<Observable<String>> to Observable<String>, so we can process the string (in this case file contents).
NB: Mapping a value to an observable then unwrapping that inner observable as we’ve done here is an extremely common operation in Rx.js, and can be achieved using the .mergeMap(fn) shorthand, which is the equivalent of .map(fn).mergeAll().
Emitting Only When Contents is Changed
When our script starts, newFiles$ will emit each filename once when chokidar first scans our _posts directory, and this will be merged into changesAndAdditions$. While editing a post in your text editor, each time you "save" the Markdown file, changedFiles$ will emit the filename, regardless of whether the contents of the file actually changed. If you hit ^S ten times in a row, changesAndAdditions$ will emit that filename 10 times and we'll read the file 10 times.
If the file contents hasn't changed, we don't want to send it down the pipe to be parsed, templated, and written as an updated HTML file-- we only want to do this latter processing (right now just console.log(contents)) if the contents are actually different from the last contents that were emitted. Luckily, Rx.js has a method for this built in: .distinctUntilChanged will emit a value one time, but will not emit again until the value changes. That means if a file is saved 10 times with the same contents, it will emit the file contents the first time and drop the rest.
const latestFileContents$ = fileContents$.distinctUntilChanged();
latestFileContents$.subscribe(content => console.log(content));
Now we'll only see file contents logged if it's different from the last contents that were emitted. There's a logic problem here, however. Consider the following scenario:
- Save
foo.mdchangesAndAdditions$emits "foo.md"fileContents$emits "contents of foo.md"- last value (
null) is distinct from "contents of foo.md" - last value updated to "contents of foo.md"
latestFileContents$emits "contents of foo.md"
- Save
bar.mdchangesAndAdditions$emits "bar.md"fileContents$emits "contents of BAR.md"- last value ("contents of foo.md") is distinct from "contents of BAR.md"
- last value updated to "contents of BAR.md"
latestFileContents$emits "contents of BAR.md"
- Save
foo.mdagainchangesAndAdditions$emits "foo.md"fileContents$emits "contents of foo.md"- last value ("contents of BAR.md") is distinct from "contents of foo.md"
- last value updated to "contents of foo.md"
latestFileContents$emits "contents of foo.md"
As you can see, the contents of the two files never changes, but the latestFileContents$ considers it "changed" because it's different from the last value, which was from the other file. The solution is to create an observable of file contents that is distinct until changed for each file, so the new contents of foo.md are compared to the last contents of foo.md, regardless of whether bar.md was changed since then. This is a bit more complicated than merging the newFiles$ and changedFiles$ Observables, but it's doable!
Because we want one observable of file changes per file, we must perform the "read file & see if it changed" per file, not on a merged stream of all files. The plan of attack is as follows: For each add event (new file created or read on startup)...
- Create an Observable of
changeevents for this file only - Start that Observable by emitting the filename once (for the
addevent) - Map the filename to an Observable of the file contents (as above)
- Use
.mergeAllto unwrap Observable from step 3 - Emit contents only if it's distinct from the last contents
// for each added file...
const latestFileContents$ = newFiles$.map(addedName => {
// 1. create Observable of file changes...
const singleFileChangesAndAdditions$ = changedFiles$
// ...only taking those for THIS file
.filter(changedName => changedName === addedName)
// 2. emit filename once to start (on "add")
.startWith(addedName);
const singleFileLatestContents$ = singleFileChangesAndAdditions$
// 3. map the filename to an observable of the file contents
.map(filename => readFileAsObservable(filename, 'utf-8'))
// 4. Merge the Observable<Observable<file contents>> to Observable<file contents>
.mergeAll()
// 5. don't emit unless the file contents actually changed
.distinctUntilChanged();
// 6. return an observable of changes per added filename
return singleFileLatestContents$;
})
.mergeAll(); //unwrap per-file Observable of changes
We're using .mergeAll twice because we're mapping strings to Observables twice:
- filename string from
changedFiles$mapped to an observable of file contents in step 4 - filename string from
newFiles$mapped to an observable returned in step 6
Because we go Observable<String> to Observable<Observable<String>> twice, we have to reverse the process with .mergeAll twice.
Since we have one singleFileChangesAndAdditions$ observable per file added, we are able to perform the "map filename to contents and compare with last value" check per file. latestFileContents$ can still be consumed as it was before.
Templating and Writing HTML to Disk
That was a lot, but it's the bulk of the Rx.js logic for our "write blog posts" goal. Now that we have an Observable that emits the contents of our Markdown blog posts each time they change, we can map that over our frontmatter, markdown parsing, template, and write-to-disk functions much as we did before with Promises. We'll start by creating a few utility functions as before:
const md = require('markdown-it')();
const frontmatter = require('frontmatter');
const pug = require('pug');
const writeFileAsObservable = Rx.Observable.bindNodeCallback(fs.writeFile);
const renderPost = pug.compileFile(`${__dirname}/templates/post.pug`);
// IN: { content, data : { title, description, ...} }
// OUT: { content, title, description, ... }
function flattenPost(post){
return Object.assign({}, post.data, { content : post.content });
}
// parse markdown to HTML then send the whole post object to the template function
function markdownAndTemplate(post){
post.body = md.render(post.content);
post.rendered = renderPost(post); //send `post` to pug render function for post template
return post;
}
// take post object with:
// 1. `slug` (e.g. "four-es6-tips") to build file name and
// 2. `rendered` contents: the finished HTML for the post
// write this to disk & output error or success message
function writePost(post){
var outfile = path.join(__dirname, 'out', `${post.slug}.html`);
writeFileAsObservable(outfile, post.rendered)
.subscribe({
next: () => console.log('wrote ' + outfile),
error: console.error
});
}
NB: see the previous post for details on frontmatter, md.render, etc.
We use our Observable utility functions to string them together:
latestFileContents$
.map(frontmatter) // trim & parse frontmatter
.map(flattenPost) // format the post for Pug templating
.map(markdownAndTemplate)// render markdown & render template
.subscribe(writePost);
Now we have a working, Rx.js version of our Static Site Generator that does the same as it did with Promises, but with built-in file watch and rebuild!
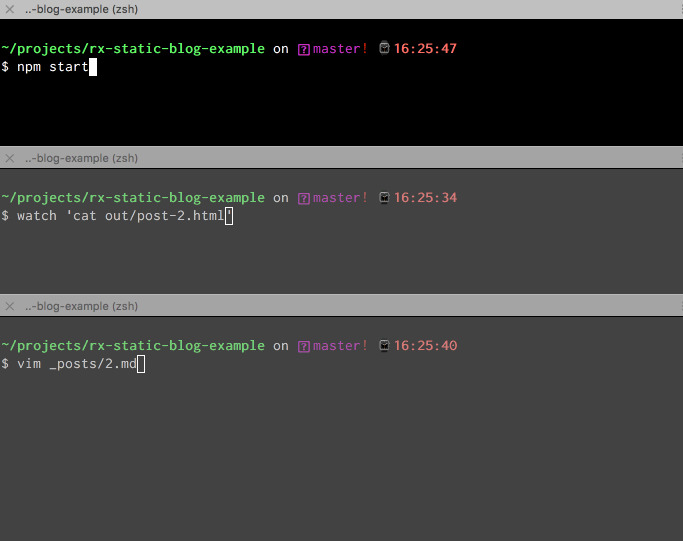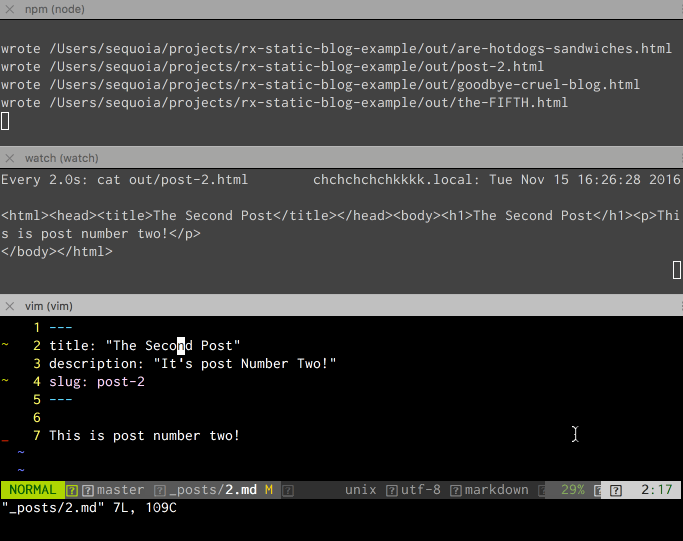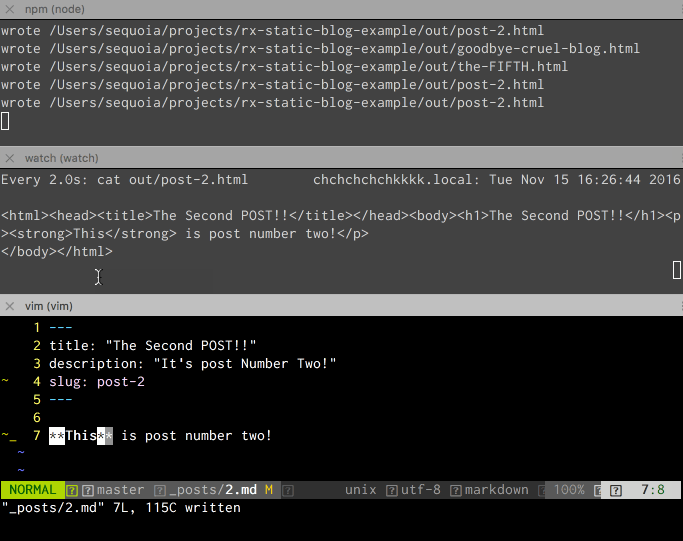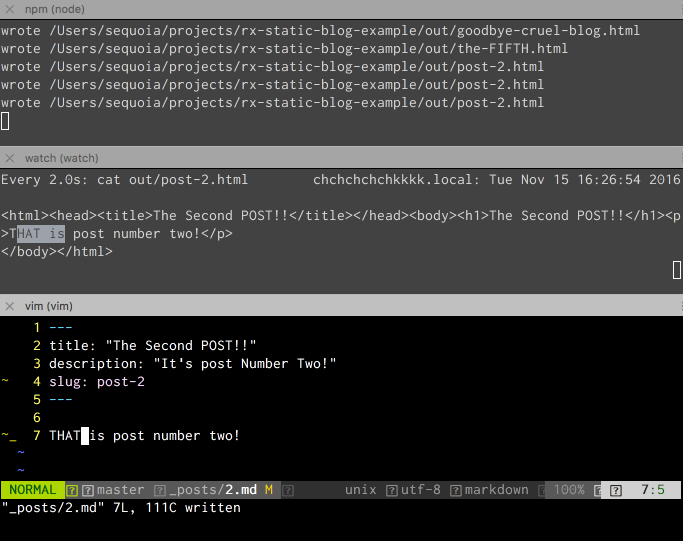
On to our next goal, the index page...
Goal 2: Write Index Page with Latest Post Metadata
Our index page template, index.pug:
html
head
title Welcome to my blog!
body
h1 Blog Posts:
//- Output h2 with link & paragraph tag with description
for post in posts
h2: a.title(href='/' + post.slug + '.html')= post.title
p= post.description
The data our template expects must be structured thus:
{
posts : [
{ title:"Intro To Rx.js", slug: "intro-to-rx-js", description: "..."},
{ title:"Post Two", slug: "post-2", description: "..."},
//...
]
}
An Observable of Post Metadata
Earlier, we mapped the latestFileContents$ over the frontmatter function. We need to use that Observable for our index page as well, so let's modify our code from above to capture that Observable and set it aside:
const postsAndMetadata$ = latestFileContents$
.map(frontmatter);
postsAndMetadata$ //same as before:
.map(flattenPost)
.map(markdownAndTemplate)
.subscribe(writePost);
The frontmatter function returns an object with data and contents keys, but we only need the value of data for our index page template so we'll pluck that property from the object:
const metadata$ = postsAndMetadata$
.pluck('data');
At this point we have an Observable that emits latest metadata for a file when that file is created or saved. We need to transform our Observable ("collection over time") to an array ("collection over space"). Rx.js's has a reduce method that can do this, but it waits for an Observable to "complete" before emitting one final "reduced" value, and our file-watching $metadata Observable never "completes."
We need a way to aggregate values into an accumulator like reduce does, but that emits the new accumulator value on each iteration so we don't have to wait for the "complete" that will never come. Rx.js has a method called .scan that does just this:
const metadataMap$ = metadata$
.scan(function(acc, post){
acc[post.slug] = post;
return acc;
}, {});
By making the slug the keys in the acc object, there will be only one property per post. When we first start our script, we'll get a post object from $metadata with the slug post-2 and add it to the accumulator as acc['post-2'].
When post two is updated and saved, its metadata will be sent to .scan again, but it won't add a new key to acc: it will overwrite the existing acc['post-2']. In this way, metadataMap$ will emit an object containing the latest metadata for all posts, with one key per post. The output will look thus:
{
'intro-to-rx-js' : { title, description, slug },
'post-2' : { title, description, slug }
}
Transforming the Data for Pug.
We now have an object with an entry for each post, but this does not match the format we outlined above ({ posts : [ post, post, post ] }). In the next two steps we can transform the object into an array and then insert it into a wrapper object:
const indexTemplateData$ = metadataMap$
.map(function getValuesAsArray(postsObject){ // (or Object.values in ES2017)
// IN: { 'slug' : postObj, 'slug2' : postObj2, ... }
return Object.keys(postsObject)
.reduce(function(acc, key){
acc.push(postsObject[key]);
return acc;
}, []);
// OUT: [postObj, postObj2, ...]
})
.map(function formatForTemplate(postsArray){
return {
posts : postsArray
};
})
Reducing Repetition and Noise
Now we get have an Observable that emits the latest listing of post metadata, formatted for the index.pug template, on each add or change event. This isn't quite what we want, however, for two reasons.
First: in the course of editing a post, most of your changes will be to content, not to the metadata. Content changes don't affect the index page, so we want to drop any emissions from indexTemplateData$ where the data is the same as the previous emission. This is another case where .distinctUntilChanged comes in handy:
const distinctITD$ = indexTemplateData$
.distinctUntilChanged(function compareStringified(last, current){
//true = NOT distinct; false = DISTINCT
return JSON.stringify(last) === JSON.stringify(current);
});
We pass a comparator function to distinctUntilChanged this time because formatForTemplate (above) returns a newly created object each time-- the new object it emits will always be "distinct" from the last one, even if their contents are identical. We stringify the last and current objects in order to compare their contents and emit only when they differ.
Second: when we first start our script, it reads each file and emits its contents once. This means that while files are initially being read, indexTemplateData$ will emit a bunch of incomplete objects consisting of whatever posts have been read so far. If we have 4 posts, emissions will look like this:
{ post1 }{ post1, post2 }{ post1, post2, post3 }{ post1, post2, post3, post4 }
Only the last version represents a collection of metadata from all pages; the others can be ignored. In order to get around the flood of events on indexTemplateData$ on startup, we'll use .debounceTime, which will wait until an Observable stops emitting for a fixed amount of time before emitting the latest result:
const distinctDebouncedITD$ = distinctITD$
.debounceTime(100); // wait 'til the observable STOPS emitting for 100ms, then emit latest
This probably isn't the most graceful solution, but when indexTemplateData$ gets its initial flood of emissions, distinctDebouncedITD$ will only emit once, once it's finished.
Writing the Index Page
The only thing left is to pass the values from distinctDebouncedITD$ to the template rendering function then write the results to disk:
const renderIndex = pug.compileFile(`${__dirname}/templates/index.pug`);
function writeIndexPage(indexPage){
var outfile = path.join(__dirname, 'out', 'index.html');
writeFileAsObservable(outfile, indexPage)
.subscribe({
next: () => console.log('wrote ' + outfile),
error: console.error
});
}
postsListing$
.map(renderIndex)
.subscribe(writeIndexPage);
Now index.html will be rewritten when we edit a post, but only if the metadata changed:
That's it!
Conclusion and Next Steps
If you made it this far, congratulations! My goal was not to explain each Rx.js concept introduced herein in detail, but to walk through the process of using Rx.js to complete a real-world programming task. I hope this was useful! If this post has piqued your interest, I highly recommend running the full version of the code this post was based on, which you can find in this repository. As always, if you have any questions or Rx.js corrections please feel free to contact me. Happy coding!
Comments
This is a great overview - thank you! What are you using to do those awesome terminal gifs?
- Mark,
Thanks, Mark! I use licecap to make gifs on my Macintosh. Tips to keep the sizes/zoom consistent:
- Use a tiling tool like Spectacle to tile to e.g. ¼ screen
- Use the same screen resolution when recording these gifs. If you switch from desktop to laptop you'll get different zoom
See my post on avoiding livecoding in demos for more such tricks!
📝 Comments? Please email them to sequoiam (at) protonmail.com